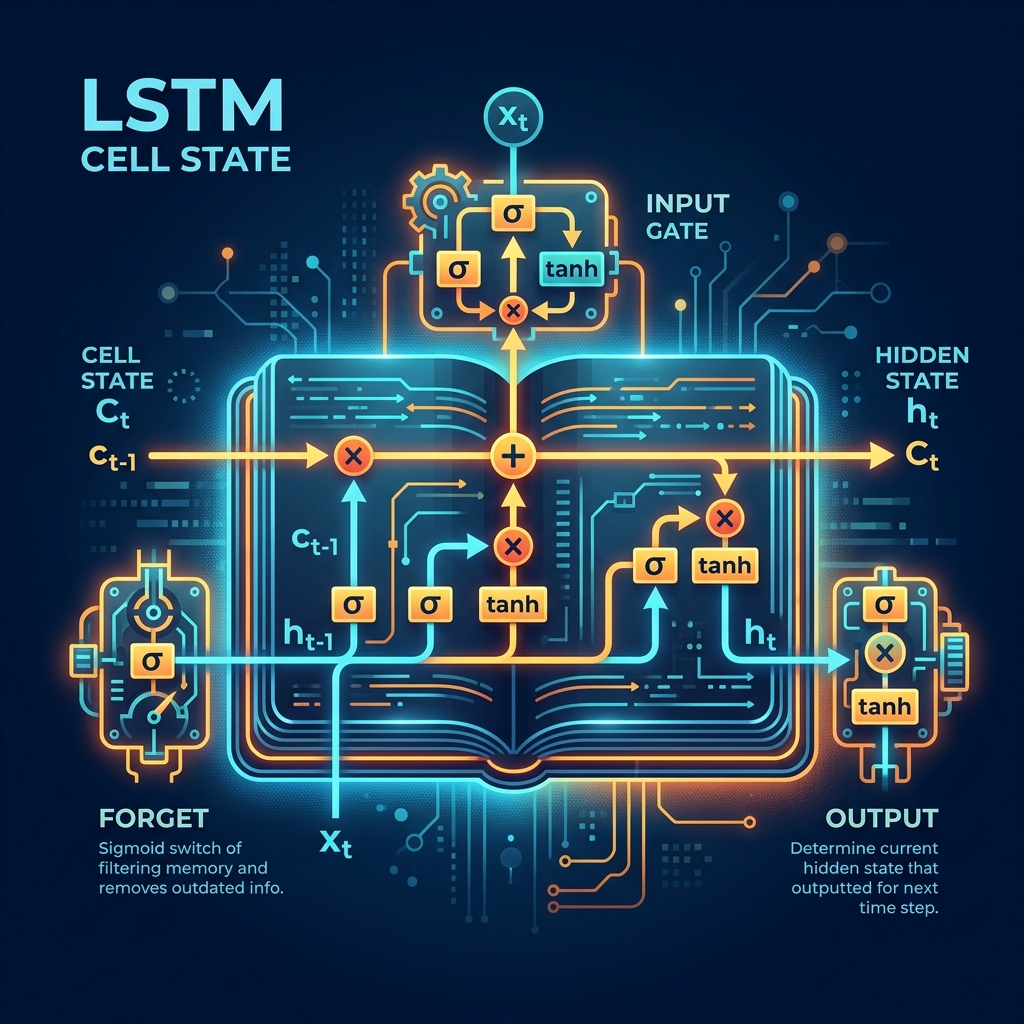
RNN: Passing the Baton
Instead of looking at a fixed "N" window, a Recurrent Neural Network (RNN) passes a Hidden State forward at every step.
Like a baton in a relay race, each character adds its information to the baton and hands it to the next character.
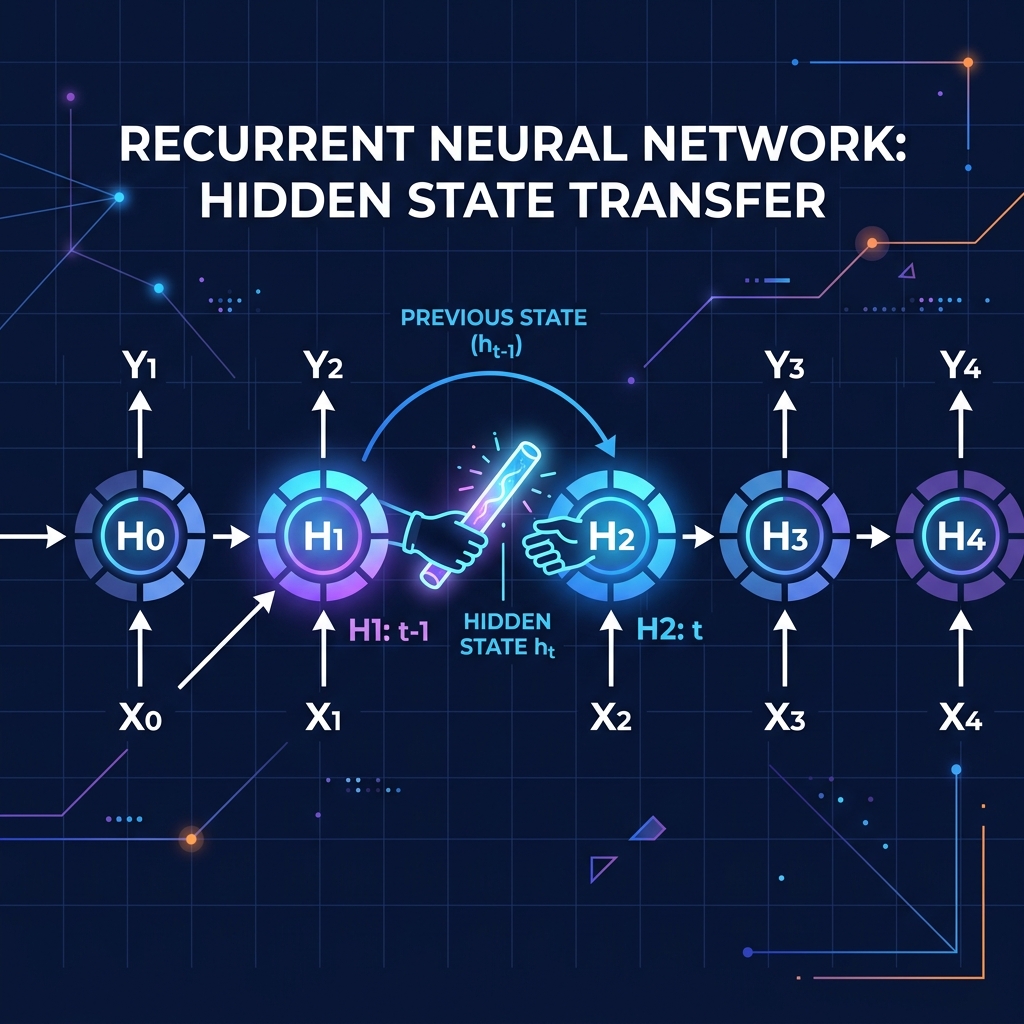
The Fatal Flaw: Vanishing Gradient
While the baton pass makes sense conceptually, it fails mathematically on long sequences.
Just like a massive game of "Telephone", the original message is constantly overwritten and distorted at every step.
By the time an RNN reaches the end of a 13-letter word, it has almost entirely forgotten the first 3 letters.
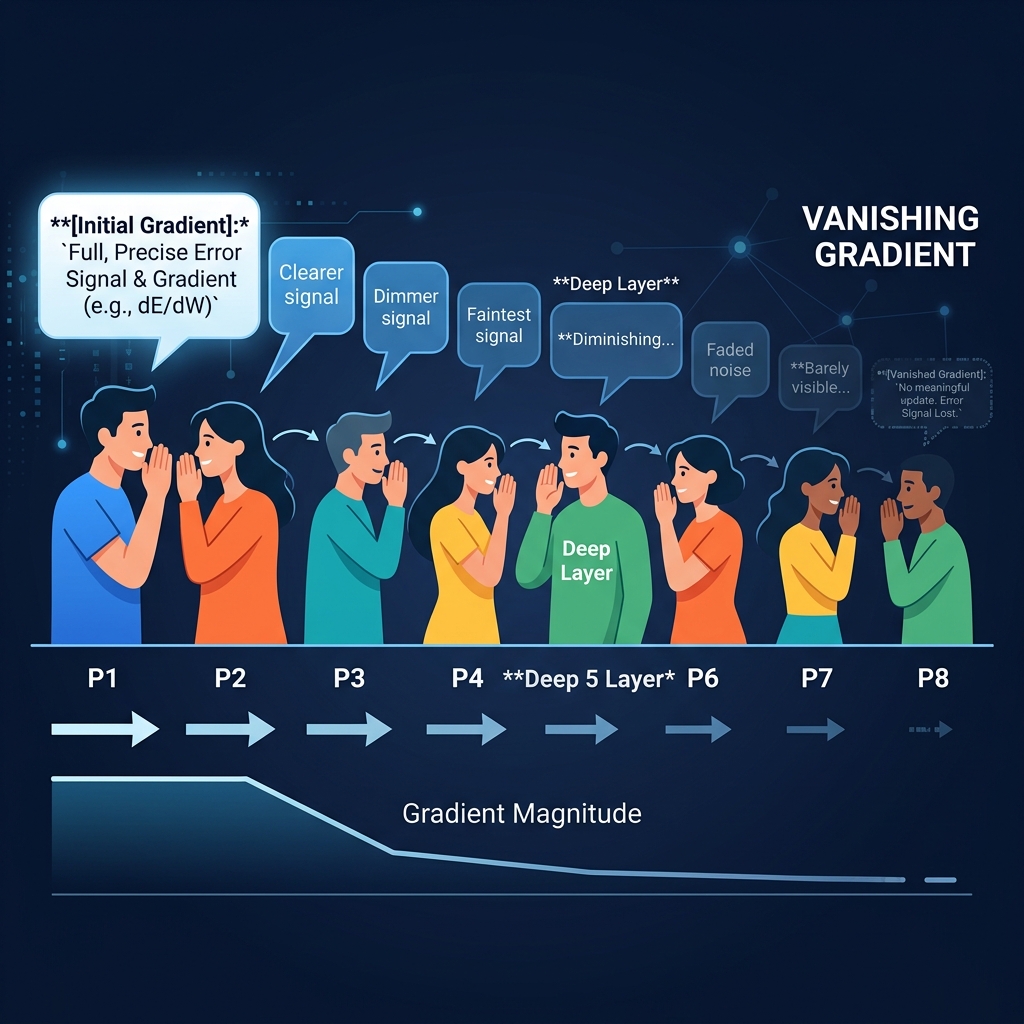
LSTM: The Smart Notebook
To fix this amnesia, the Long Short-Term Memory (LSTM) was invented. It introduces a Cell State—a separate track of memory that acts like a smart notebook.
- Forget Gate: Decides what old information to erase.
- Input Gate: Decides what new information to write down.
- Output Gate: Decides what to output as the current Hidden State.