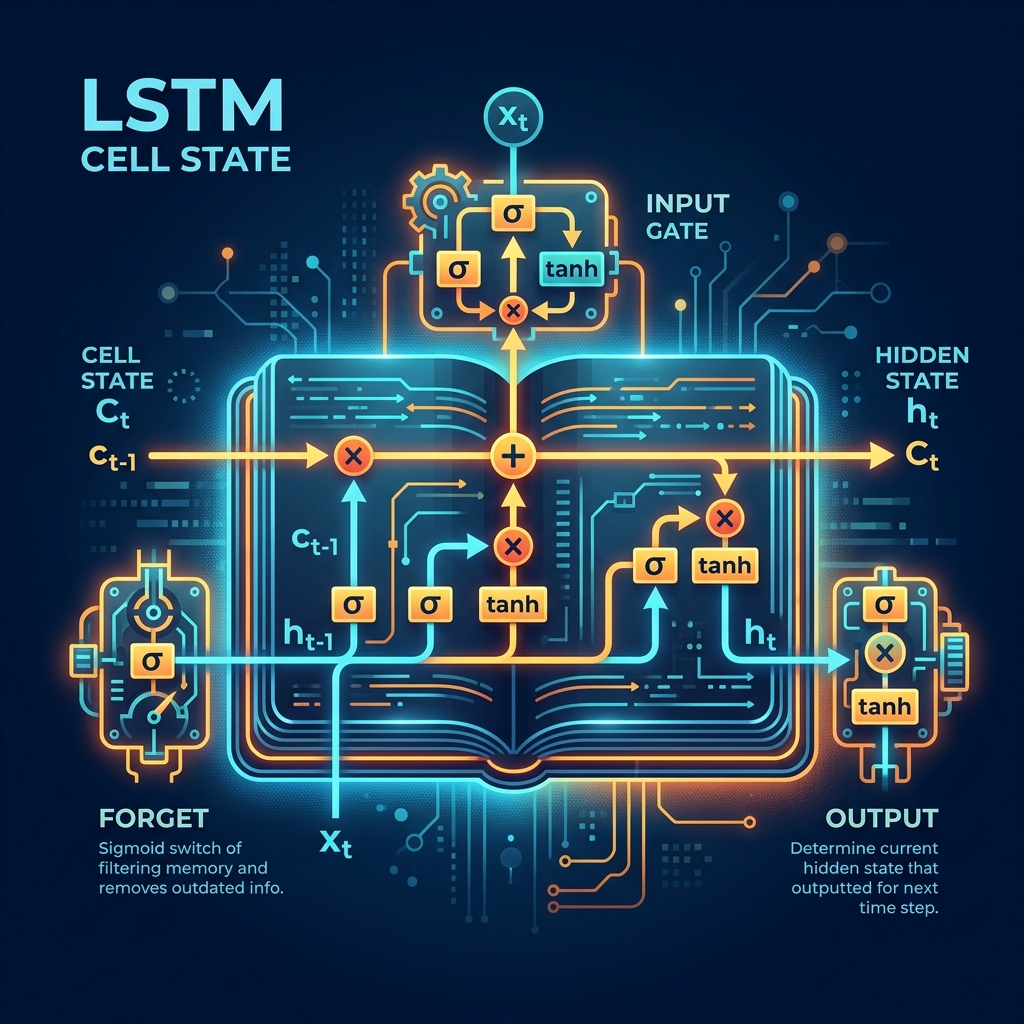
RNN: Baton-ஐ கைமாற்றுதல்
குறிப்பிட்ட "N" எழுத்துக்களை மட்டும் பார்க்காமல், Recurrent Neural Network (RNN) ஒவ்வொரு படியிலும் ஒரு Hidden State-ஐ முன்னோக்கி அனுப்புகிறது.
ஒரு தொடர் ஓட்டப்பந்தயத்தில் (relay race) baton-ஐ கைமாற்றுவது போல, ஒவ்வொரு எழுத்தும் தனது தகவலை baton-ல் சேர்த்து, அடுத்த எழுத்திடம் ஒப்படைக்கிறது. இது முந்தைய அனைத்தையும் ஒரே vector-க்குள் சுருக்குகிறது.
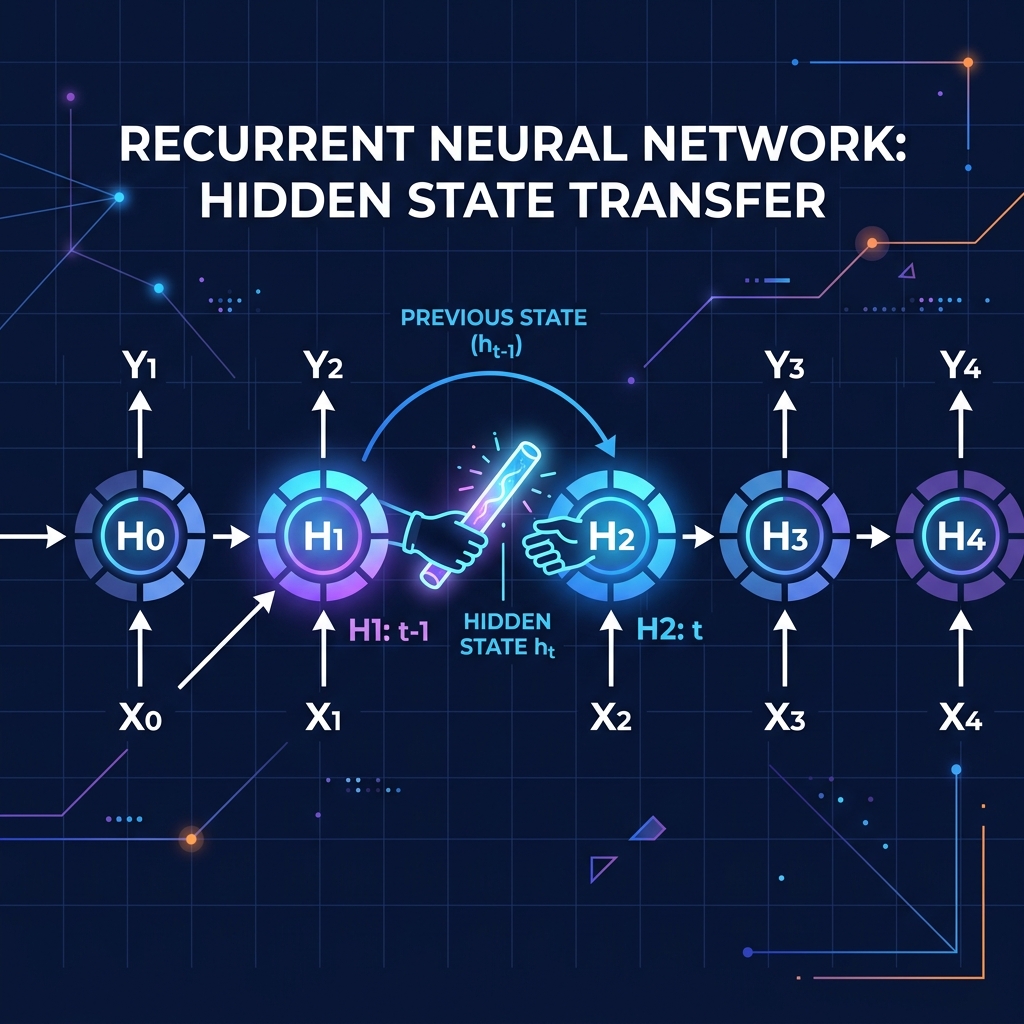
முக்கிய குறைபாடு: Vanishing Gradient
Baton-ஐ கைமாற்றும் முறை அடிப்படையில் சரியாகத் தோன்றினாலும், நீண்ட sequences-க்கு கணிதரீதியாக இது தோல்வியடைகிறது.
"Telephone" விளையாட்டு போல, அசல் செய்தி ஒவ்வொரு படியிலும் தொடர்ந்து மேலெழுதப்பட்டு, சிதைந்துவிடுகிறது.
ஒரு RNN 13-எழுத்து வார்த்தையின் முடிவை அடையும் போது, அது முதல் 3 எழுத்துக்களை கிட்டத்தட்ட முழுமையாக மறந்துவிடுகிறது.
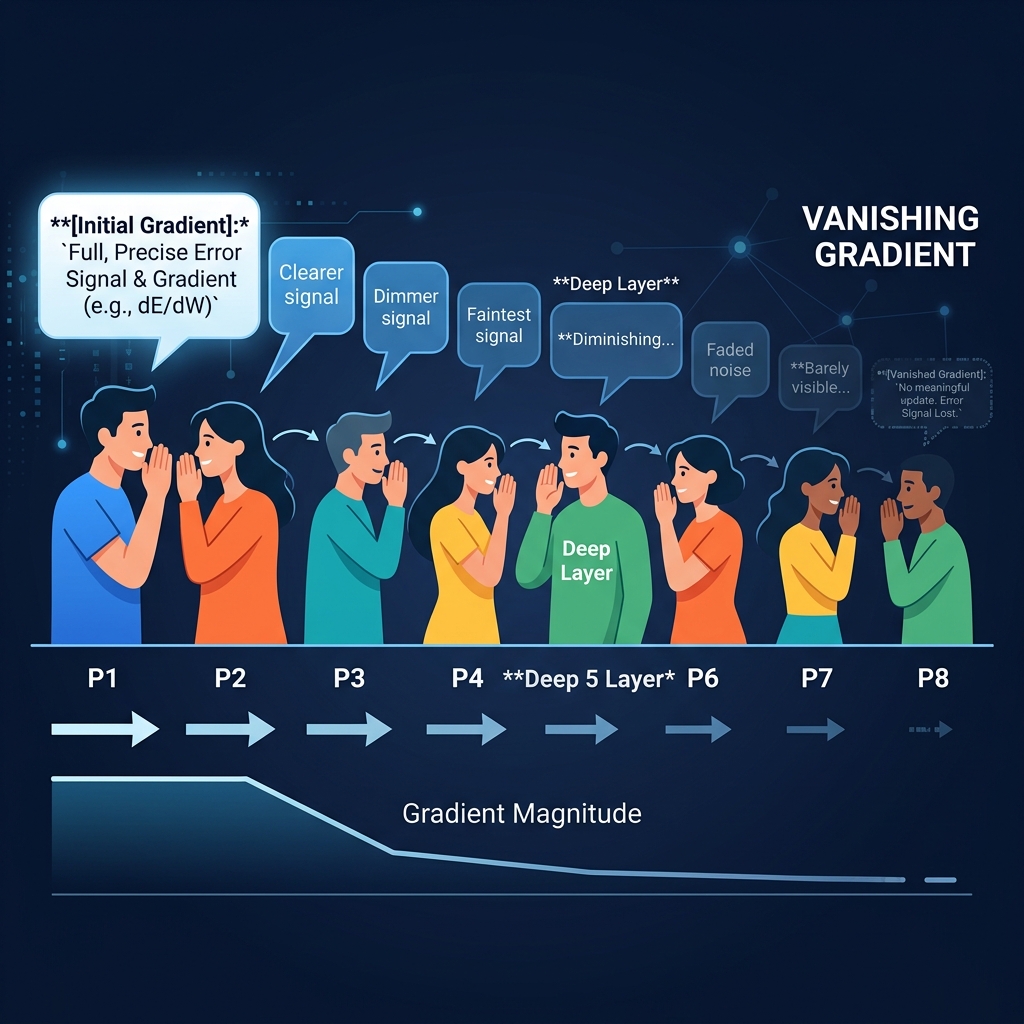
LSTM: ஒரு Smart Notebook
இந்த மறதியை சரிசெய்ய, Long Short-Term Memory (LSTM) உருவாக்கப்பட்டது. இது Cell State என்ற ஒன்றை அறிமுகப்படுத்துகிறது—இது ஒரு smart notebook போல செயல்படும் தனி நினைவாற்றல் பாதை.
- Forget Gate: எந்த பழைய தகவலை அழிக்க வேண்டும் என்பதை முடிவு செய்கிறது.
- Input Gate: எந்த புதிய தகவலை எழுதி வைக்க வேண்டும் என்பதை முடிவு செய்கிறது.
- Output Gate: தற்போதைய Hidden State-ஆக எதை வெளியிட வேண்டும் என்பதை முடிவு செய்கிறது.