19. Vanishing Gradient Problem
Whisper Down the Lane
பிழைத் தகவல் (Gradient) கடைசி அடுக்கிலிருந்து முதல் அடுக்குக்குப் பின்னோக்கிச் செல்லும்போது (Backprop), அதன் மதிப்பு மெல்ல மெல்லக் குறைந்து முதல் அடுக்கில் 'சுழியமாக' மறைந்துவிடுகிறது (Vanish).
நீண்ட வரிசையில் நிற்கும் நபர்களிடம் ஒரு ரகசியத்தைச் சொல்லும்போது, அது முதல் நபரைச் சென்றடையும் முன் சிதைந்து போவதைப் போல!
இதனால்தான் பல ஆண்டுகளாக ஆழமான வலைப்பின்னல்களைப் பயிற்றுவிக்க முடியவில்லை. இன்று ReLU, LSTM போன்ற நுட்பங்கள் இதைத் தீர்த்துள்ளன.

20. GANs: கலைஞனும் விமர்சகனும்
Generative Adversarial Networks (GANs)
2014-ல் இயன் குட்ஃபெலோ அறிமுகப்படுத்திய கணினிகளின் “கற்பனைத் திறன்”. இதன் அடிப்படை இரண்டு AI-களுக்கிடையேயான போட்டி!
- ஜெனரேட்டர் (கலைஞன்): இதன் வேலை, உண்மையான படைப்புகளைப் போலவே, புதிய போலிப் படைப்புகளை உருவாக்குவது.
- டிஸ்கிரிமினேட்டர் (விமர்சகன்): இதன் வேலை, உண்மையான படைப்பையும், போலிப் படைப்பையும் ஒப்பிட்டு, எது போலி என்பதைக் கண்டுபிடிப்பது.
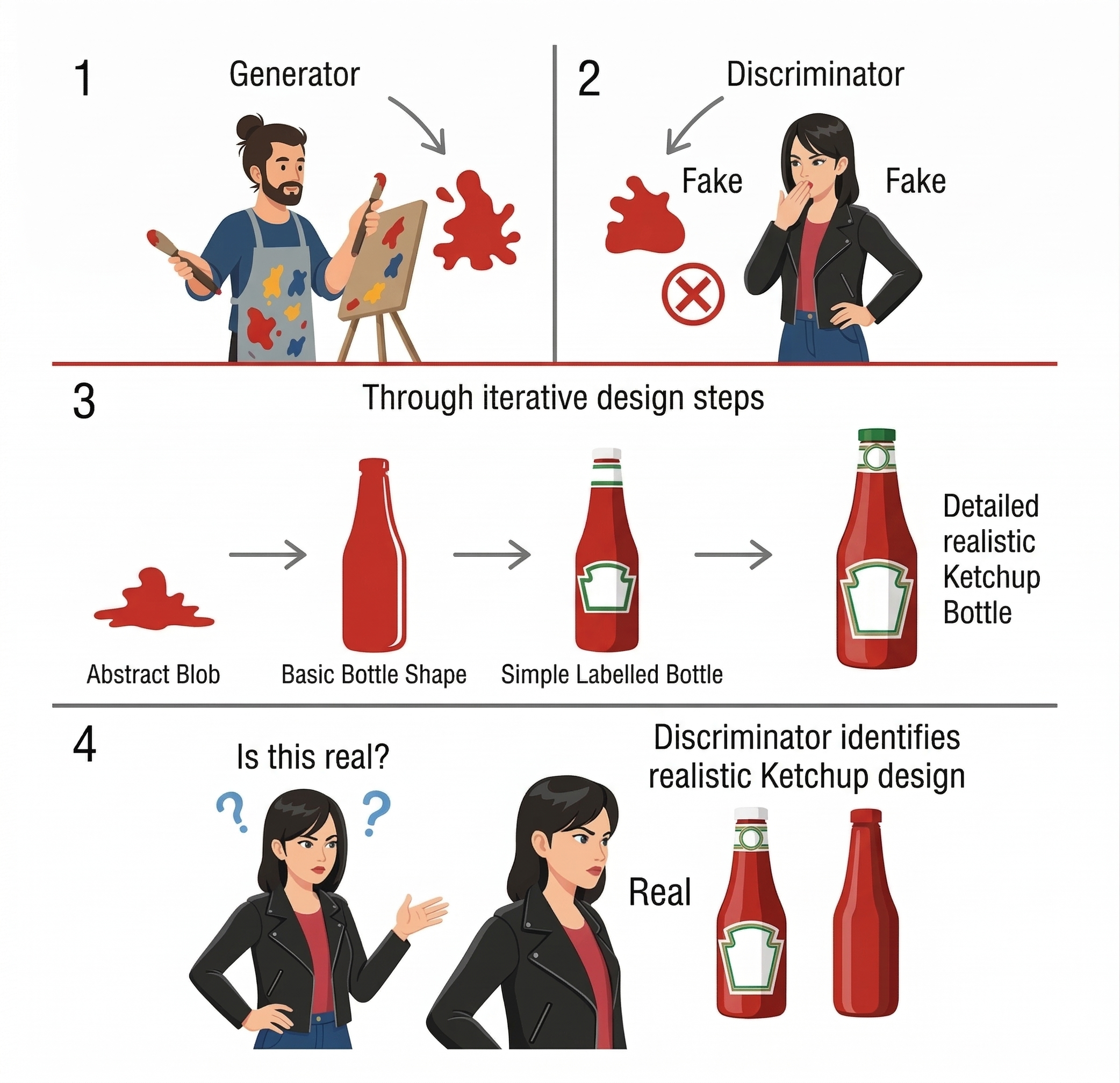
21. GAN-களின் கற்றல் சுற்று & சவால்கள்
கெட்சப் பாட்டில் பயிற்சி
முதல் முயற்சி: கலைஞன் களிம்பு போல ஒன்றை வரைகிறான். விமர்சகன் "இது போலி" என நிராகரிக்கிறான்.
ஆயிரக்கணக்கான முயற்சிகள்: கலைஞன் பாடம் கற்றுக்கொண்டு பாட்டில் வடிவத்திற்கு முன்னேறுகிறான். ஒரு கட்டத்தில் விமர்சகனாலேயே உண்மையா, பொய்யா எனப் பிரிக்க முடிவதில்லை!
படைப்பாற்றலின் இருமுனைக் கத்தி
- Deepfakes: போலியான செய்தி வீடியோக்களை உருவாக்கிச் சமூகத்தில் குழப்பம் ஏற்படுத்துதல்.
- Mode Collapse: கலைஞன் ஒரே ஒரு உத்தியை மட்டும் கற்றுக்கொண்டு, அதையே திரும்பத் திரும்ப உருவாக்குதல்.
22. டிரான்ஸ்ஃபார்மர்கள் மற்றும் LLM-கள்
இதுவே இன்று நாம் காணும் ChatGPT, Gemini போன்ற உரையாடல் AI-களின் அடித்தளம்.
- அடுத்த வார்த்தையைக் கணிப்பது (Next-Token Prediction): இணையப் பக்கங்களைப் படித்து, புள்ளியியல் ரீதியாக அடுத்த வார்த்தையை ஊகிப்பது.
- கவனத்தின் சக்தி (Attention Mechanism): நீண்ட வாக்கியத்தில் எந்த வார்த்தைகளுக்கு அதிக முக்கியத்துவம் கொடுக்க வேண்டும் என்பதைத் தீர்மானிக்கிறது.
உ-ம்: "மலைகளின் ராணியான ஊட்டி, மிகவும் குளிர்ச்சியாக இருந்தது" - குளிர்ச்சியாக என்பதை ஊட்டியோடு இணைத்துப் புரிதல்.