Building LLMs for Tamil Language
A Tokenization Perspective
Moving from "Translated AI" to "Native AI"
Open Source
Linguistic Integrity
The Tokenizer Case
If Gemini 3.0 / GPT-5.2 is already good at Tamil, why do we need to build our own?
The Core Question
Proprietary (Gemini 3.0/GPT-5.2)
- Excellent Performance
- Black Box (Cannot inspect)
- Pay per Token (Expensive)
- Data Privacy Concerns
Open Source (Tamil LLMs)
- Full Control & Privacy
- Run on Local Hardware
- Current models are inefficient
- Requires Custom Tokenizer
1. The "Token Tax"
Cost & Efficiency Disparity
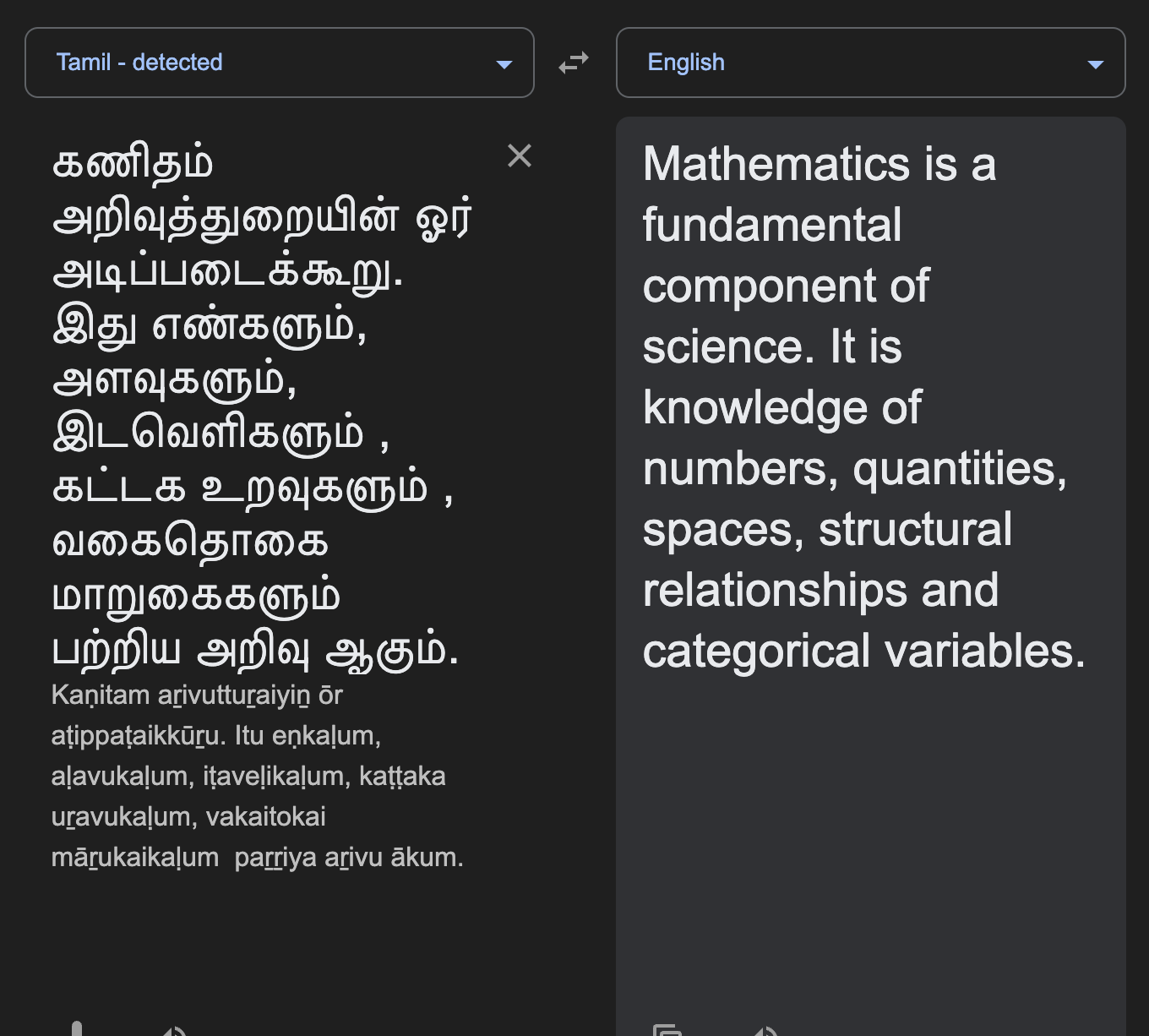
Impact: Inference costs 3x more. Generation is 3x slower.
Visualizing Tokenization: English
Standard Tokenizers on English Text
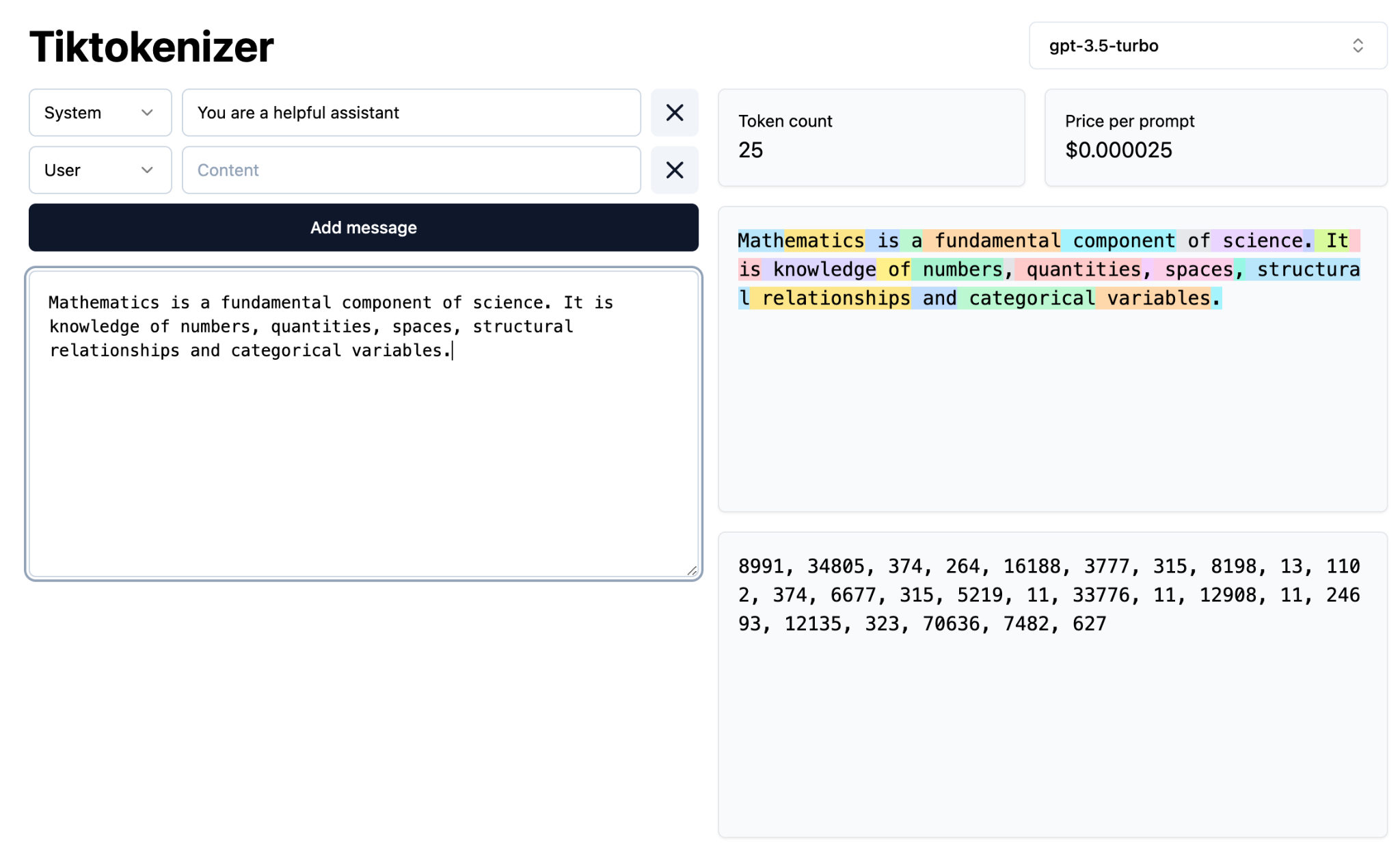
25
Tokens
Visualizing Tokenization: Tamil
Standard Tokenizers on Tamil Text
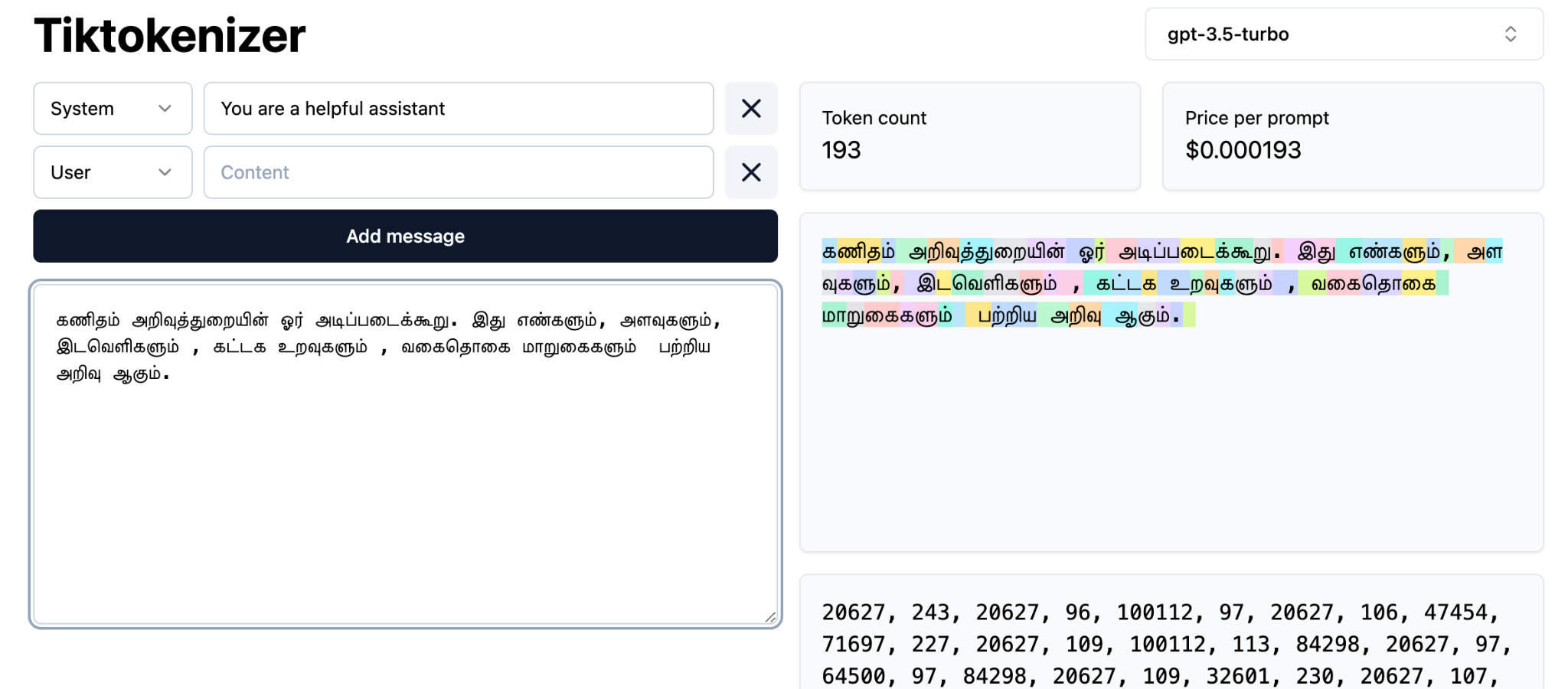
High
Fragmentation
Notice the fragmentation. Tamil words are chopped into meaningless bytes, destroying semantic context.
Case Study: GPT-5.2 Tokenization
Even the best models struggle
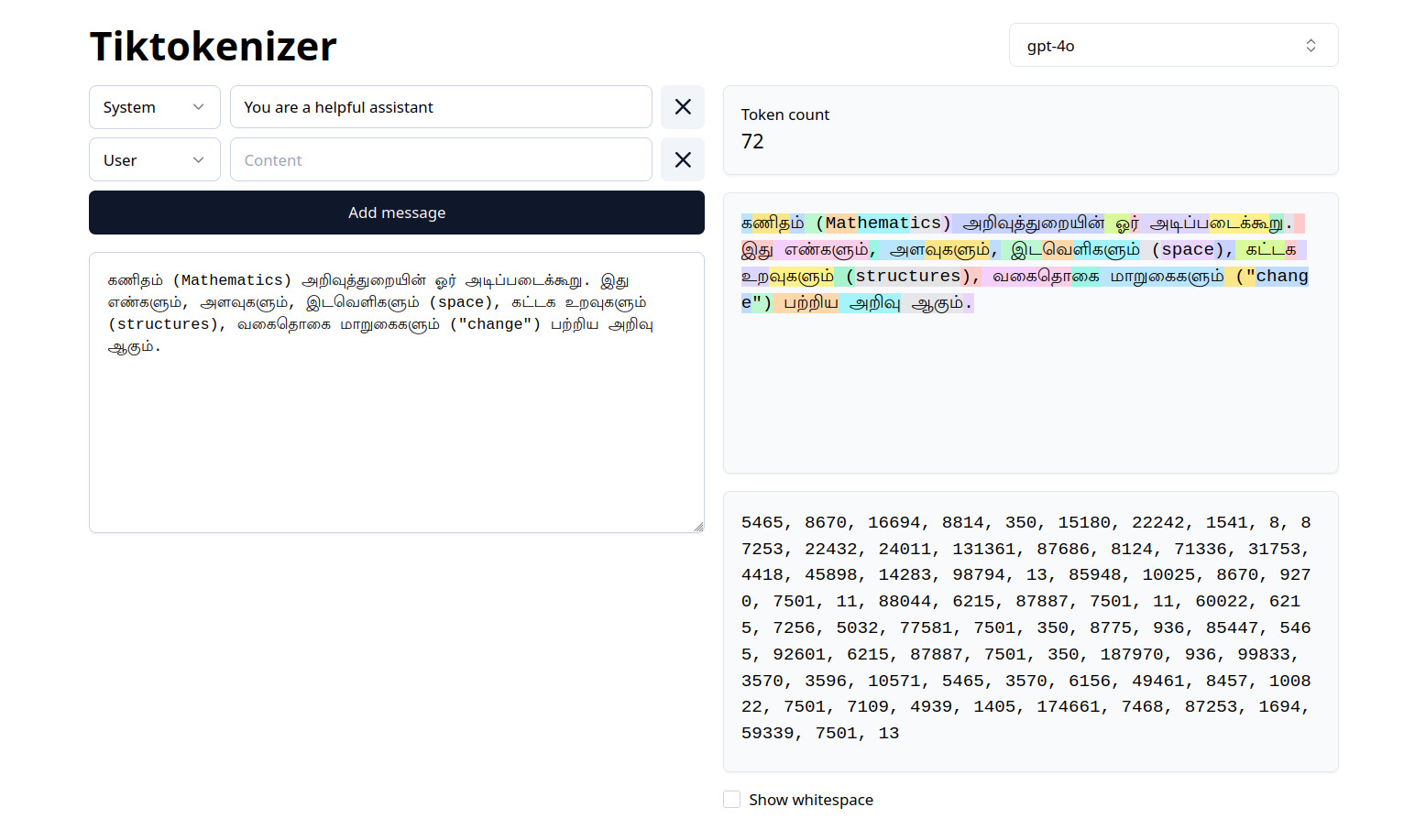
72
Tokens
Observation: A short paragraph of ~25 words consumes 72 tokens (Ratio: ~2.9 tokens/word).
2. The Context Window Collapse
English Model
Reads 50 pages
Tamil (Standard Tokenizer)
Reads only 15 pages
Problem: LLM memory is fixed (e.g., 4096 tokens).
Result: Because Tamil is "bloated" with tokens, the model's effective memory shrinks. It "forgets" the start of long documents.
Tamil Tokens
| Word | உறவுகளும் | உறவுகளையும் | உறவுகளை |
|---|---|---|---|
| Tamil Llama tiny | _உறவ-களும்- | _உறவ-களையும்- | _உறவ-களை |
| Tamil Llama | _உ-ற-வு-களும்- | _உ-ற-வு-களையும்- | _உ-ற-வு-களை |
- Byte Pair Encoding though successfully finds out actual Tamil words
- by just relying frequency of byte pairs, it heavily depends upon the corpora.
- It is fascinating to see a smaller model figure out good part of the Tamil word உறவு whereas larger model did not
Tamil Tokens (Contd.)
| Word | கணிதமானது | எண்கணக்கியலில் |
|---|---|---|
| Tamil Llama tiny | _கணித-மானது- | _எண-க்-கண-க்கிய-லில்- |
| Tamil Llama | _கணித-மானது- | _எண்-கண-க்கிய-லில்- |
| Word | இடவெளிகளும் | முக்கோணம் |
|---|---|---|
| Tamil Llama tiny | _இட-வெ-ள-ிகளும்- | _முக்கோணம்- |
| Tamil Llama | _இட-வெளி-களும்- | _மு-க்கோ-ணம்- |
Tamil Tokens (Case Study 2)
| Word | முத்திரட்சி | நால் திரட்சி | பல்திரட்சி |
|---|---|---|---|
| Preferred* | முத்-திரட்சி | நால்-திரட்சி | பல்-திரட்சி |
| Tamil Llama tiny | முத்திர-ட- ்சி | _ந- ால்- _திர- ட- ்சி | பல- ்த- ிர-ட- ்சி |
| Tamil Llama | மு-த்திர-ட்சி | _ந- ால்- _தி-ர-ட்சி | பல்-திர-ட்சி |
- Even within the same model, the திரட்சி is tokenized differently because,
- BPE is a heuristic method and has no idea what the language words look like
- even whether it is text or some other data.
3. Linguistic Integrity
Why "Search" algorithms fail Tamil
| Feature | English | Tamil |
|---|---|---|
| Structure | Distinct Words | Agglutinative (Root + Suffixes) |
| Example | "Interdisciplinary" | "முத்திரட்சி" (Muthiratchi) |
| Standard Split | Inter + disciplinary (Logical) |
மு + த்திர + ட + சி (Nonsense Noise) |
| Consequence | Learns Meaning | Learns Character Patterns only |
Solution: A custom tokenizer respects Tamil grammar, keeping roots and suffixes intact.
Thodarudai (தொடருடை)
Open Source Morphological Tokenizer - IN PROGRESS

Vanangamudi (Selvakumar Murugan)
The Bias Reality
Global LLM Training Data (e.g., Llama 3 / GPT-5.2)
Result: Models treat Tamil as a translation task, not a native thinking task.
The "Infinite Corpus" Strategy
Solving Combinatorial Explosion
Project Madurai (Lit) + News (Modern) + Govt (Formal)
Ensure root "Mathematics" appears as
கணிதம், கணிதத்தில், கணிதத்தை...
Why? Wikipedia is too static. To learn Tamil grammar, the model must see roots combined with every possible suffix.
The 3 Pillars of Data
1. Pre-Training
"The Knowledge"
Raw text from books, web, and archives.
Goal: Learn Grammar & Facts.
2. Instruct Tuning
"The Behavior"
Native instructions (not translated).
Ex: "Write a petition to the VAO."
3. Synthetic
"The Reasoning"
Using Gemini to generate logic puzzles in Tamil.
Goal: Advanced Reasoning.
Conclusion
We are not just building a model.
We are preserving Digital Sovereignty for the Tamil language.
Thank You